
9 The Perception Pipeline: How Brains and CNNs See the World
Learning Objectives By the end of this chapter, you will be able to:
- Trace the journey of visual information from the eye to high-level processing areas in the brain.
- Explain the concept of a receptive field and how it enables hierarchical feature detection.
- Connect the architecture of the brain’s visual cortex directly to the layers of a Convolutional Neural Network (CNN).
- Compare how biological vision and AI models achieve object recognition and spatial awareness.
- Implement simple visual filters in Python that mimic the first steps of neural image processing.
9.2 4.1 The Visual Pathway: A Journey Through the Brain
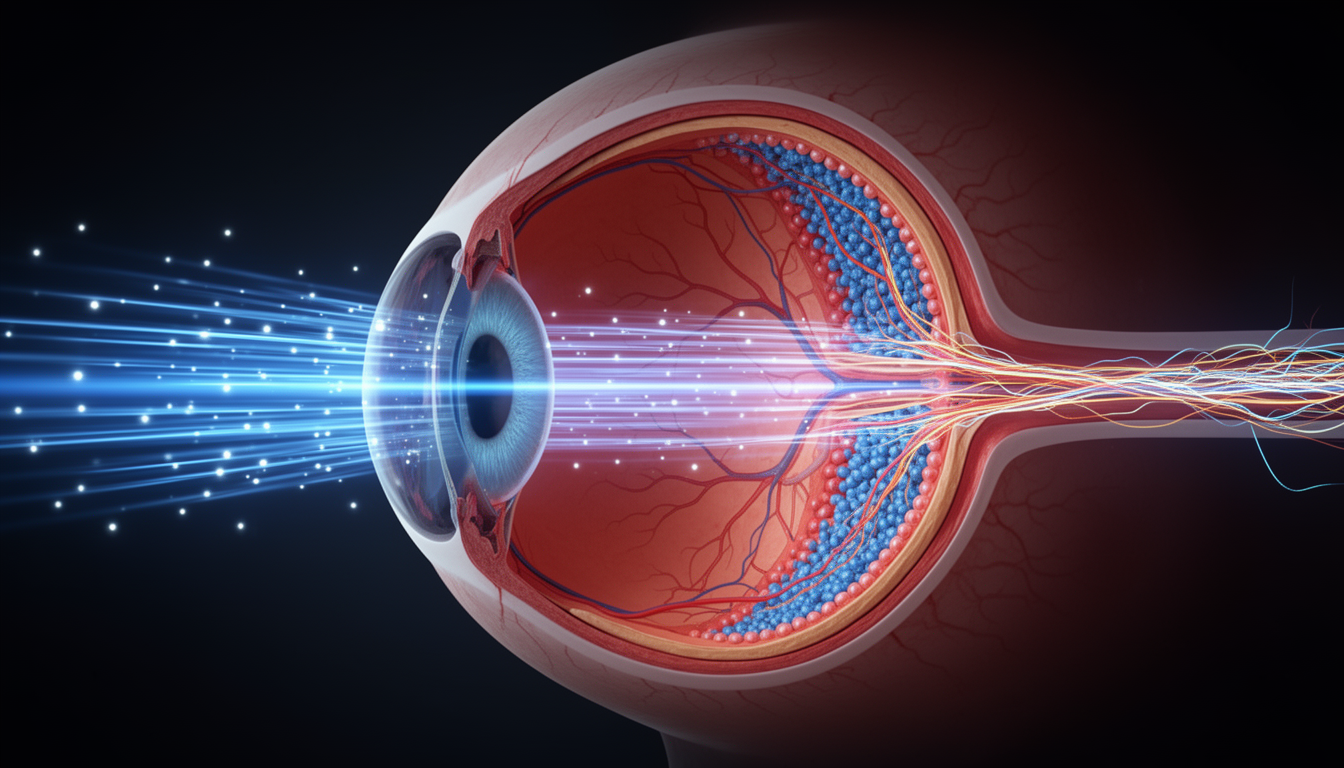
Our visual journey begins not in the brain, but in the retina, a layer of neural tissue at the back of the eye. The retina is not just a sensor; it’s a sophisticated pre-processor.
- Retina: Photoreceptors (rods and cones) capture light. A network of other cells immediately gets to work, enhancing contrasts and detecting edges. By the time the signal leaves the eye, it has already been significantly processed.
- LGN (Lateral Geniculate Nucleus): The signals travel to this relay station in the thalamus, which sorts them and routes them to the cortex.
- V1 (Primary Visual Cortex): This is the first cortical stop. Here, the brain breaks the visual scene down into its most basic components: lines, edges, and motion in specific orientations.
From V1, the information famously splits into two streams, a concept that has directly inspired AI architectures.
The “What” and “Where” Streams: A Division of Labor
- Ventral Stream (“What” Pathway): This pathway travels down towards the temporal lobe. Its job is object recognition. As information moves along this stream (V1 -> V2 -> V4 -> IT Cortex), neurons respond to increasingly complex shapes, from simple curves to entire objects like faces or cars. This is the brain’s image classification pipeline.
- Dorsal Stream (“Where/How” Pathway): This pathway travels up into the parietal lobe. Its job is spatial awareness and action. It figures out where objects are, how they are moving, and how you can interact with them. This is the brain’s object detection and motor control pipeline.
This elegant division of labor allows the brain to process identity and location in parallel, a highly efficient strategy.
 Figure 4.1: The visual processing pathway, showing the split into the dorsal (“Where/How”) and ventral (“What”) streams after the initial processing in the primary visual cortex (V1).
Figure 4.1: The visual processing pathway, showing the split into the dorsal (“Where/How”) and ventral (“What”) streams after the initial processing in the primary visual cortex (V1).
9.3 4.2 Receptive Fields: A Neuron’s Window on the World
The fundamental concept for understanding both biological and artificial vision is the receptive field. A neuron’s receptive field is simply the small patch of the visual world that it “sees” or responds to.
- In the retina, receptive fields are simple circles with a center-surround structure (e.g., excited by light in the center, inhibited by light in the surround). This makes them excellent contrast detectors.
- In V1, Hubel and Wiesel’s Nobel Prize-winning work showed that receptive fields are tuned to bars of light with specific orientations. A “vertical” neuron will fire vigorously at a vertical edge but will ignore a horizontal one.
This is the first step in building a feature hierarchy. Just as letters combine to form words, and words combine to form sentences, the brain combines simple features to build complex perceptions.
The Hierarchy of Vision: Simple to Complex

- Simple Cells (in V1): Respond to an oriented edge at a specific location.
- Complex Cells (in V1/V2): Respond to an oriented edge anywhere within their receptive field. They achieve this by pooling the inputs from several simple cells. This builds translation invariance, a critical property for recognizing an object regardless of its exact position.
- Hypercomplex Cells (End-Stopped): Respond to more specific features like corners, curves, or line endings.
This progression—from points of light to oriented lines to corners and curves—is the brain’s method for building a rich visual vocabulary from the ground up.
 Figure 4.2: The hierarchy of receptive fields. Simple center-surround fields in the retina are combined to create oriented bar detectors in V1, which are then combined to detect more complex patterns in higher visual areas.
Figure 4.2: The hierarchy of receptive fields. Simple center-surround fields in the retina are combined to create oriented bar detectors in V1, which are then combined to detect more complex patterns in higher visual areas.
9.4 4.3 The Uncanny Parallel: CNNs as Artificial Visual Systems
When you understand the brain’s visual hierarchy, the architecture of a Convolutional Neural Network becomes incredibly intuitive. A CNN is, in essence, a computational model of the ventral visual stream.
 Figure 4.3: The striking parallel between the hierarchical processing in the primate visual cortex and the layered architecture of a typical Convolutional Neural Network.
Figure 4.3: The striking parallel between the hierarchical processing in the primate visual cortex and the layered architecture of a typical Convolutional Neural Network.
Core Architectural Parallels
- Convolutional Layers as Receptive Fields: A filter (or kernel) in a convolutional layer is a direct analog of a neuron’s receptive field. It’s a small window that slides over the input image, looking for a specific pattern (like a vertical edge).
- Weight Sharing: The network uses the same filter across the entire image. This is analogous to how the brain uses the same “vertical edge detector” template everywhere in the visual field. It’s massively efficient.
- Hierarchical Layers: CNNs stack layers on top of each other.
- Early Layers learn to detect simple features like edges and colors, just like V1.
- Mid-Layers combine these edges to form textures, corners, and simple shapes, just like V2 and V4.
- Deep Layers combine these parts to recognize complex objects, just like the Inferior Temporal (IT) cortex.
- Pooling Layers as Complex Cells: A max-pooling layer takes the maximum response from a small region. This is a direct implementation of the complex cell principle: it preserves the feature information while discarding precise location information, thereby building translation invariance.
Beyond Basic CNNs: The Modern AI Connection
- Vision Transformers (ViTs): While CNNs mimic the local receptive field structure, ViTs take a different, also biologically plausible approach. They break an image into patches (similar to how attention might focus on different parts of a scene) and use a self-attention mechanism to learn the relationships between them. This is analogous to the brain’s ability to use top-down attention and long-range connections to understand the global context of a scene, not just its local features.
- Generative Models (GANs, Diffusion Models): These models learn to create images, not just classify them. This is deeply connected to the theory of predictive coding in the brain, which posits that our brain is constantly generating predictions about what it expects to see and updating its internal model based on the error between its prediction and the actual sensory input.
9.5 4.4 Code Lab: Seeing Like a Machine
Let’s use Python to explore these foundational concepts.
Implementing Gabor Filters (V1 Simple Cells)
A Gabor filter is a mathematical model of the receptive fields of simple cells in V1. It’s a sine wave modulated by a Gaussian, perfect for detecting oriented edges.
Building a Simple CNN Layer
Here is a minimal PyTorch example showing how a convolutional layer and a pooling layer work together, mimicking the simple-to-complex cell transition.
Input image shape: torch.Size([1, 1, 28, 28])
V1-like (simple cell) output shape: torch.Size([1, 8, 28, 28])
V2-like (complex cell) output shape: torch.Size([1, 8, 14, 14])9.6 4.5 Key Takeaways: A Two-Way Street
The relationship between neuroscience and AI is not one of simple inspiration but of a rich, ongoing dialogue.
- Biology Provides the Blueprint: The core architectural ideas of modern computer vision—hierarchical layers, local receptive fields, and the separation of “what” and “where” processing—were discovered first by neuroscientists.
- AI Provides the Model: Building computational models like CNNs forces us to be explicit about our theories of the brain. When a CNN trained on images develops feature detectors that look just like V1 neurons, it provides powerful evidence that our understanding of the brain is on the right track.
- Convergent Evolution: Both brains and AI, faced with the same problem of making sense of a visually complex world, have arrived at remarkably similar solutions. This suggests there are fundamental and perhaps universal principles of visual processing.
- The Frontier is Recurrence and Attention: While early CNNs were purely feedforward, the future of AI vision lies in incorporating feedback, recurrence, and attention—all features that are abundant in the brain and essential for contextual understanding and dynamic perception.
Chapter Summary In this chapter, we followed the remarkable journey of light from the eye to the mind, revealing a process that has been masterfully reverse-engineered in AI.
- We traced the visual pipeline, from the pre-processing in the retina to the split into the ventral (“what”) and dorsal (“where”) streams in the cortex.
- We defined the receptive field and saw how a hierarchy of them, from simple to complex, allows the brain to build a rich vocabulary of visual features.
- We drew a direct and powerful analogy between this biological hierarchy and the architecture of a Convolutional Neural Network, where convolutional filters act as simple cells and pooling layers act as complex cells.
- We expanded this connection to modern AI, linking concepts like attention and generative models to their biological counterparts.
- Through code examples, we saw how to model the brain’s first steps in vision, creating the very filters that allow both brains and machines to see.
This chapter highlights one of the most successful examples of neuroscience inspiring AI. The principles of vision, discovered through decades of patient research, now power applications from self-driving cars to medical imaging, and they continue to guide us toward building truly intelligent systems.
9.7 4.5 Exercises
Conceptual Questions
Explain the concept of hierarchical feature detection in the visual system. How do simple cells, complex cells, and hypercomplex cells build upon each other? What computational principle does this hierarchy embody?
Compare the receptive field concept in neuroscience with convolutional filters in CNNs. What are the key similarities and differences? Why is the receptive field analogy so powerful for understanding CNNs?
Describe the “What” and “Where” visual streams. How does this functional separation relate to different tasks in computer vision (e.g., image classification vs. object detection)? Can you think of AI architectures that mirror this separation?
Explain translation invariance and its implementation in both biological and artificial vision. How do complex cells achieve translation invariance? How do pooling layers in CNNs achieve a similar property? What are the trade-offs?
Computational Problems
- Implement and visualize Gabor filters at multiple orientations. Write code to:
- Create Gabor filters at 8 different orientations (0°, 22.5°, 45°, etc.)
- Apply these filters to a natural image
- Visualize the filtered outputs and identify which edges each orientation detects
- Compare the Gabor filter responses to actual V1 neuron recordings (conceptually)
- Build a mini hierarchical vision system. Create a simple three-layer system:
- Layer 1: Edge detection using Gabor-like filters
- Layer 2: Combine edges to detect simple shapes (corners, T-junctions)
- Layer 3: Combine shapes to detect simple objects
- Test your system on simple geometric shapes and analyze what each layer learns
- Analyze the effect of pooling on translation invariance. Implement:
- A small CNN with and without max-pooling layers
- Test both models on shifted versions of the same image
- Quantify how much translation invariance pooling provides
- Discuss the trade-off between invariance and spatial precision
- Simulate center-surround receptive fields. Implement:
- On-center, off-surround receptive fields
- Off-center, on-surround receptive fields
- Apply these to an image and show how they enhance edges and contrasts
- Explain why this is an efficient first step in vision
Discussion Questions
- Vision Transformers vs. CNNs: Biological plausibility. Vision Transformers (ViTs) use attention rather than convolution. Discuss:
- Which aspects of biological vision do ViTs capture that CNNs miss?
- Do you think attention or convolution is a better model of the brain’s visual processing?
- Could the brain use both mechanisms in different areas or at different timescales?
- Limitations of the feedforward view of vision. The chapter focuses on the feedforward path from retina to higher cortex. However, the brain has massive feedback connections. Discuss:
- What role might feedback play in vision (e.g., predictive coding, attention)?
- How could recurrent connections improve AI vision systems?
- What are some real-world visual tasks that clearly require feedback (e.g., seeing through occlusions, resolving ambiguous images)?
9.8 4.6 References
Hubel, D. H., & Wiesel, T. N. (1962). Receptive fields, binocular interaction and functional architecture in the cat’s visual cortex. The Journal of Physiology, 160(1), 106-154.
Hubel, D. H., & Wiesel, T. N. (1968). Receptive fields and functional architecture of monkey striate cortex. The Journal of Physiology, 195(1), 215-243.
Goodale, M. A., & Milner, A. D. (1992). Separate visual pathways for perception and action. Trends in Neurosciences, 15(1), 20-25.
Fukushima, K. (1980). Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics, 36(4), 193-202.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), 2278-2324.
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). ImageNet classification with deep convolutional neural networks. Advances in Neural Information Processing Systems, 25, 1097-1105.
Yamins, D. L., & DiCarlo, J. J. (2016). Using goal-driven deep learning models to understand sensory cortex. Nature Neuroscience, 19(3), 356-365.
Cadieu, C. F., Hong, H., Yamins, D. L., Pinto, N., Ardila, D., Solomon, E. A., et al. (2014). Deep neural networks rival the representation of primate IT cortex for core visual object recognition. PLoS Computational Biology, 10(12), e1003963.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., et al. (2021). An image is worth 16x16 words: Transformers for image recognition at scale. International Conference on Learning Representations.
Felleman, D. J., & Van Essen, D. C. (1991). Distributed hierarchical processing in the primate cerebral cortex. Cerebral Cortex, 1(1), 1-47.
Lindsay, G. W. (2021). Convolutional neural networks as a model of the visual system: Past, present, and future. Journal of Cognitive Neuroscience, 33(10), 2017-2031.
Schrimpf, M., Kubilius, J., Hong, H., Majaj, N. J., Rajalingham, R., Issa, E. B., et al. (2018). Brain-score: Which artificial neural network for object recognition is most brain-like? bioRxiv, 407007.